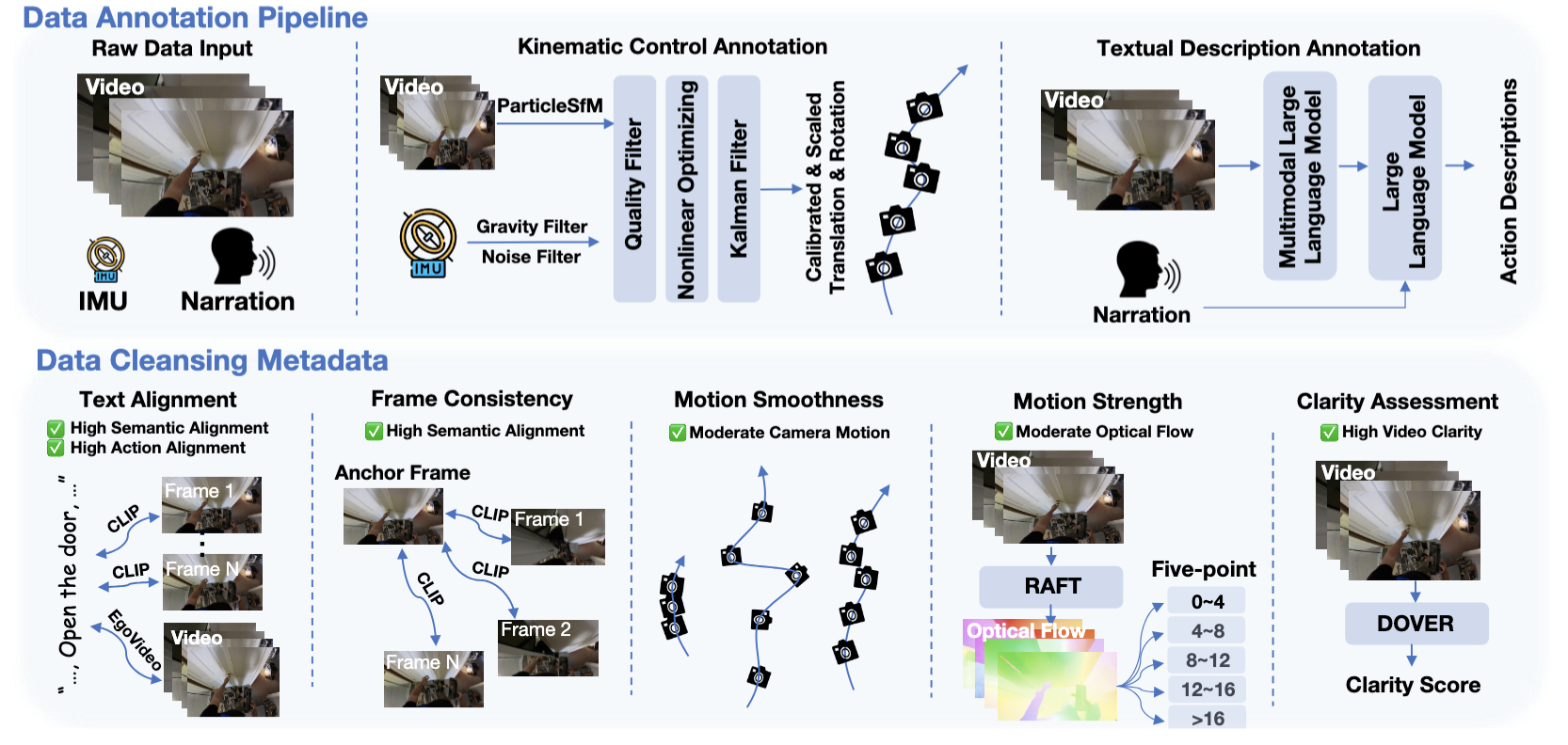
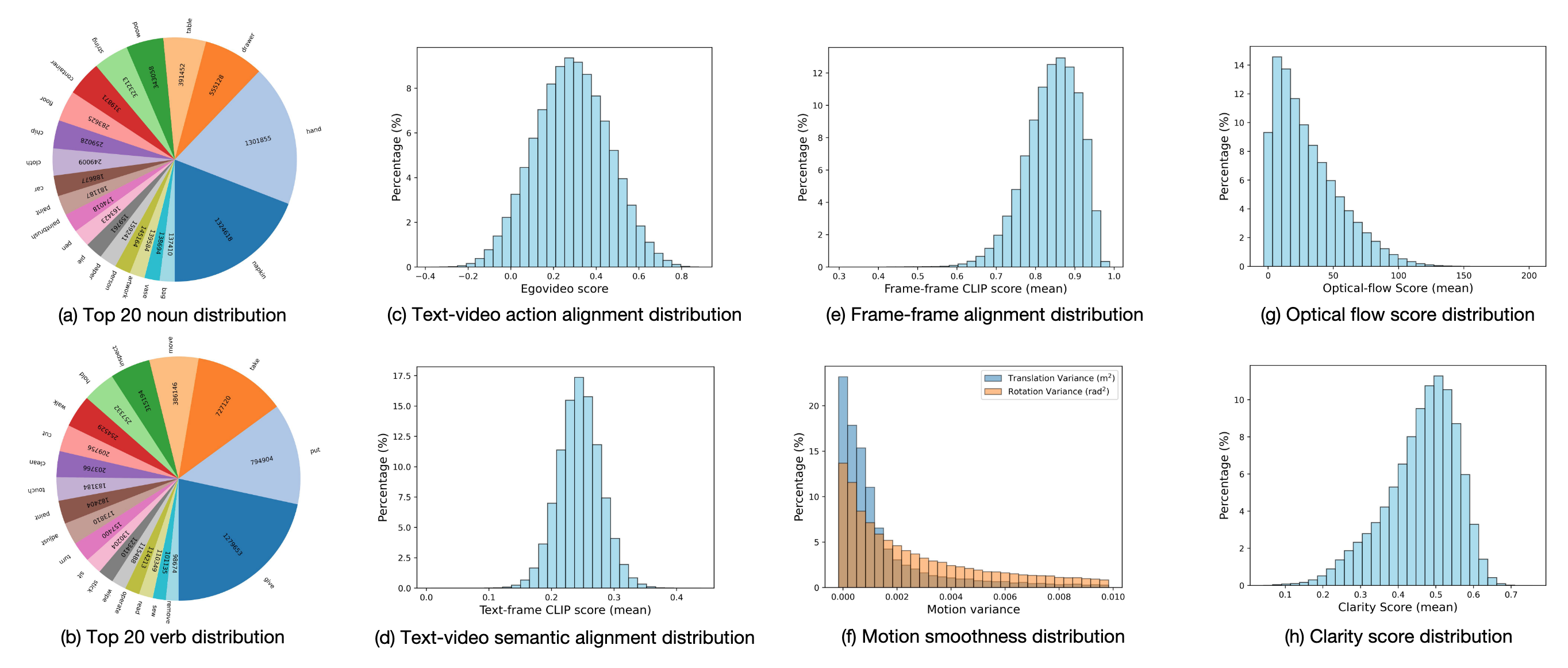
EgoVid-5M is a meticulously curated high-quality action-video dataset designed specifically for egocentric video generation. It includes detailed action annotations, such as fine-grained kinematic control and high-level textual descriptions. Furthermore, it incorporates robust data cleaning strategies to ensure frame consistency, action coherence, and motion smoothness under egocentric conditions.